


Prediction of the Fatigue Limit of PM Steel Parts by the Application of a Neural Network
Dr David Whittaker reports exclusively for ipmd.net on a presentation at Euro PM2011 that discusses this subject.
In a session on Tools for Improving PM: Modelling and Process Control at the Euro PM2011 Conference, held in Barcelona, 9-12 October, an impressive first step towards this goal was described in a presentation of a joint Iranian-German application of a Neural Network approach.
The paper was submitted by B Lofti (Shahad Chamran University, Ahvaz, Iran), S R Asadullahpour (National Iranian South Oil Company, Ahvaz, Iran) and A Zafari and P Beiss (RWTH Aachen University, Germany) and was presented, on behalf of his Iranian colleagues, by Professor Beiss.
This development has focussed on the implementation of a soft computing tool, an artificial neural network, to predict fatigue endurance limits from carefully selected inputs.
Neural networks are composed of simple elements or “neurons” that are able to simulate the neural behaviour of the human brain. Typically, neural networks are adjusted or “trained”, so that a particular input leads to a specific target (supervised training).
The input data used in this study were fatigue endurance limits for Fe-Cu-C sintered steels derived from S-N curves published in the open literature or generated by the Aachen group. Tables 1 and 2 define the ranges of the parameters covered by these data.
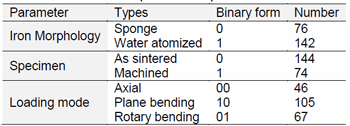
(From paper by B Lofti, etal, ‘Prediction of the Fatigue Limit of PM Steel Parts by the Application of a Neural Network’ presented at EuroPM2011 Conference. Published in the Conference Proceedings by EPMA, UK)
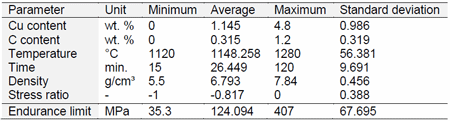
Table 2 Description of the quantitative data
(From paper by B Lofti, etal, ‘Prediction of the Fatigue Limit of PM Steel Parts by the Application of a Neural Network’ presented at EuroPM2011 Conference. Published in the Conference Proceedings by EPMA, UK)
Before network training, an attempt was made to identify redundant parameters that would not contribute to the accuracy of the network. Firstly, heat treated data were disregarded because of the limited number of datasets in this category. Sintering atmosphere variations were also ignored as they did not contribute to the accuracy of the neural model. Finally, sintering temperature and time were combined and contracted to the Larson-Miller parameter, P, defined as
P = T (20 + log t)
where T is the temperature in degrees Kelvin and t is the sintering time in hours.
An initial sensitivity analysis was used to define the network architecture that gave the lowest error.
To evaluate the accuracy of this model, the database was divided into 3 portions. The first 70% of the datasets was used for the training process, the next 15% was used for validation and the remaining 15% was used for blind testing of the trained network against a completely new dataset.
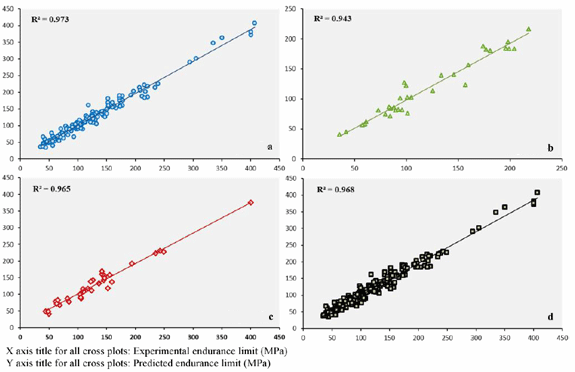
Fig. 1 Cross-plots of experimenta; endurance limits versus those predictedby the neural network for (a) training, (b) validation. (c) testing and (d) overall data. (From paper by B Lofti, etal, ‘Prediction of the Fatigue Limit of PM Steel Parts by the Application of a Neural Network’ presented at EuroPM2011 Conference. Published in the Conference Proceedings by EPMA, UK)
The cross-plots of experimental versus predicted values of all datasets are presented in Fig. 1. The level of correlation in these plots is highly encouraging.
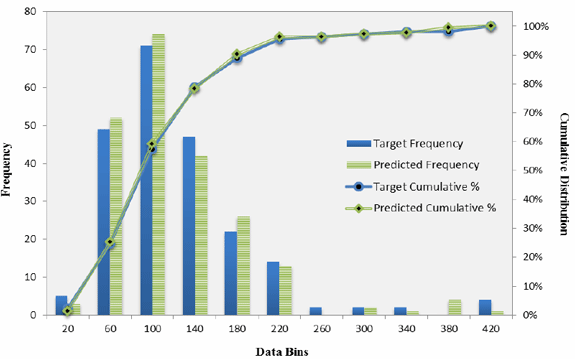
Fig. 2 True and predicted endurance limit histogram and cumulative distribution functions (From paper by B Lofti, etal, ‘Prediction of the Fatigue Limit of PM Steel Parts by the Application of a Neural Network’ presented at EuroPM2011 Conference. Published in the Conference Proceedings by EPMA, UK)
Fig. 2 presents the histograms and cumulative distribution functions of the overall experimental and predicted data. This figure indicates that the neural network had been well trained and that the true distribution of data around the mean had been very well simulated by the model.
The correlation between experimental and predicted data is defined on the basis of a range of statistical parameters in Table 3. The worst-case average absolute error of 9.207% and average relative error of -1.568% prove that the network had successfully modelled the input data with an acceptable margin of error.
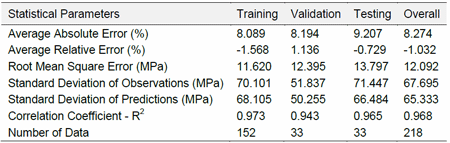
Table 3 Different statistical parameters regarding the trained neural model
(From paper by B Lofti, etal, ‘Prediction of the Fatigue Limit of PM Steel Parts by the Application of a Neural Network’ presented at EuroPM2011 Conference. Published in the Conference Proceedings by EPMA, UK)
The reliable network was subsequently coupled with a “genetic algorithm” to construct a robust system to efficiently design experiments aimed at a specific endurance limit value.
The genetic algorithm was subjected to a number of practical constraints, as given in Table 4. 7.0 g/cm3 was set as the practical limit of density in cold compaction. In sintering, the process becomes expensive beyond P = 27441 (1120oC, 30 minutes). Powder mixes with more than 0.8%C have reduced flowability and more than 2% Cu gives excessive growth in sintering.

Table 4 Constraints applied to the genetic otimization
(From paper by B Lofti, etal, ‘Prediction of the Fatigue Limit of PM Steel Parts by the Application of a Neural Network’ presented at EuroPM2011 Conference. Published in the Conference Proceedings by EPMA, UK)
As can be seen from Table 4, endurance limits of 250 MPa and 190 MPa respectively were set as the targets for R = -1 and R = 0.
The experimental designs provided by the genetic algorithm are presented in Table 5. For R = -1, no exact match was achieved although one design did achieve 244 MPa. Evidently, without high temperature sintering, a fully reversed fatigue strength of 250 MPa cannot be achieved at 7.0 g/cm3 density, 2.0% Cu and 0.8% C. On the other hand, all of the presented cases for R = 0 exactly matched the target. For both stress ratios, the target values could not be reached under axial loading.
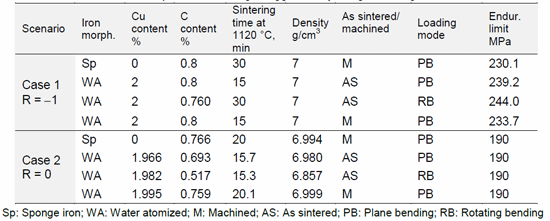
Table 5 Experimental design suggested by the genetic algorithm
(From paper by B Lofti, etal, ‘Prediction of the Fatigue Limit of PM Steel Parts by the Application of a Neural Network’ presented at EuroPM2011 Conference. Published in the Conference Proceedings by EPMA, UK)
The employed approach is clearly a robust tool in that it provides valuable insight into the input/output relationship within the database.
At this stage, there are limitations to what the system can achieve. For instance, predictions are possible at only the two levels of stress ratio covered in the input data, without the introduction of unacceptable levels of error i.e. interpolation between or extrapolation outside the values for R of 0 and -1 is not an option.
Notwithstanding this, the results generated so far must be viewed as highly encouraging and future contributions from these authors should be anticipated with considerable interest.
News | Articles | Market reviews | Search directory | Subscribe to e-newsletter


